Dans le cadre de ma mission de conseil auprès de la mission Etalab sur la publication des données essentielles des marchés publics, je me suis intéressé aux standards proposés par la Commission européenne pour la transmission d’informations inter-administrations, et plus particulièrement à eDelivery. Voyant qu’aucune documentation n’était disponible en français, je me suis dit qu’il pourrait être utile que je rassemble mes notes et les partage.
En bref
eDelivery est un composant issu du règlement européen Connecting Europe Facility (CEF) et un réseau fondé sur un protocole de transport de données sécurisé afin de faciliter l’échange de données et de documents entre des administrations publiques et la société civile. En général, chaque nœud de ce réseau est consacré à un seul projet impliquant des administrations de plusieurs États membres (ex : e-justice, e-administation, commande publique électronique, etc.). Ces nœuds peuvent être liés à des administrations nationales, régionales ou locales.
Les autres composants de CEF :
Le règlement CEF prévoit également le financement des infrastructures nécessaires au déploiement de ces composants.
Un réseau européen entre l’administration et la société civile
L’échange de données et de documents peut être initié entre administrations publiques (A2A), mais également entre une administration publique et une entreprise (B2A / A2B), comme l’a démontré l’implémentation PEPPOL du protocole eDelivery dans le domaine de la commande publique électronique (eProcurement).
Les administrations qui développent des portails Web peuvent utiliser eDelivery pour échanger des données et des documents avec les citoyens (A2C / C2A). Par exemple, un portail de justice en ligne à destinations des citoyens peut communiquer avec d’autres systèmes d’information.
Enfin, eDelivery peut être utilisé indifféremment pour échanger au niveau local, national, ou européen.
Un protocole standard
eDelivery utilise le protocole de messagerie AS4 (Applicability Statement 4) développé par l’OASIS, et suit les recommandations définies par les États membres dans le cadre du projet pilote e-SENS (Electronic Simple European Networked Services) qui s’est terminé en mars 2017 et a rendu ses conclusions.
Chaque administration rejoignant le réseau eDelivery peut soit installer un point d’accès, soit faire appel à un fournisseur de service et ainsi partager des données et des documents via le protocole AS4.
L’utilisation d’un protocole standard commun au niveau européen assure un échange de données simplifié et donc plus efficace et sécurisé. De nos jours, les fuites de données étant devenues un risque majeur, de cette sécurité découle une plus grande confiance dans l’échange d’information, notamment pour les documents confidentiels.
La Commission européenne détaille les avantage d’eDelivery sur [cette page]https://ec.europa.eu/cefdigital/wiki/pages/viewpage.action?pageId=46992275).
Comment ça marche ?
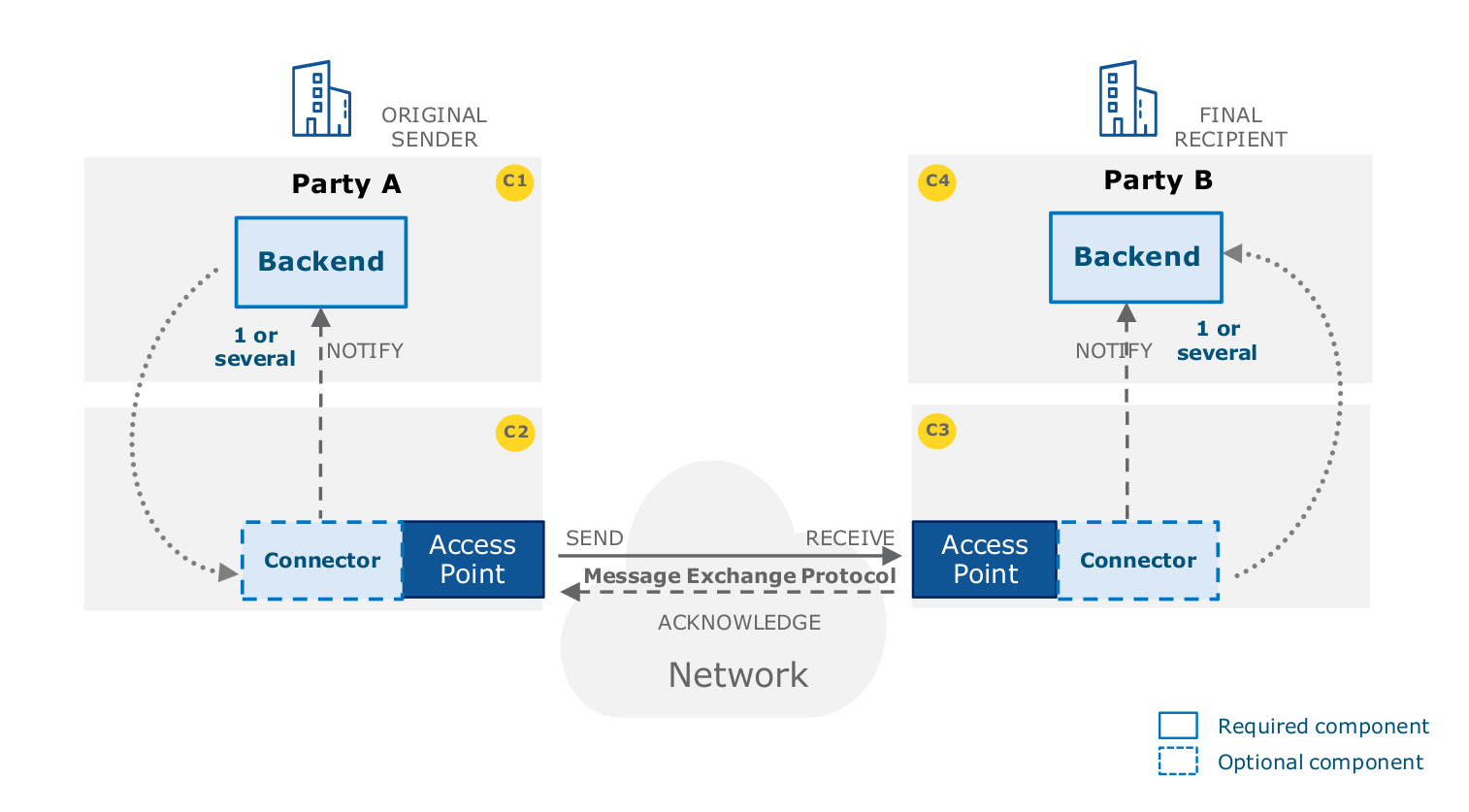
Le protocole eDelivery utilise une topologie de réseau de type « 4 coins » (4-corner topology). Cela signifie que chaque système d’information du réseau eDelivery, et par extension chaque administration, communique avec les autres membres via un point d’accès (access point) qui lui est propre, sans passé par un point d’accès central. Cette topologie se distingue par un haut niveau de décentralisation mais impose un haut niveau de conformité au standard et de sécurité. Cette topologie est également appelée un « réseau maillé » (mesh network).
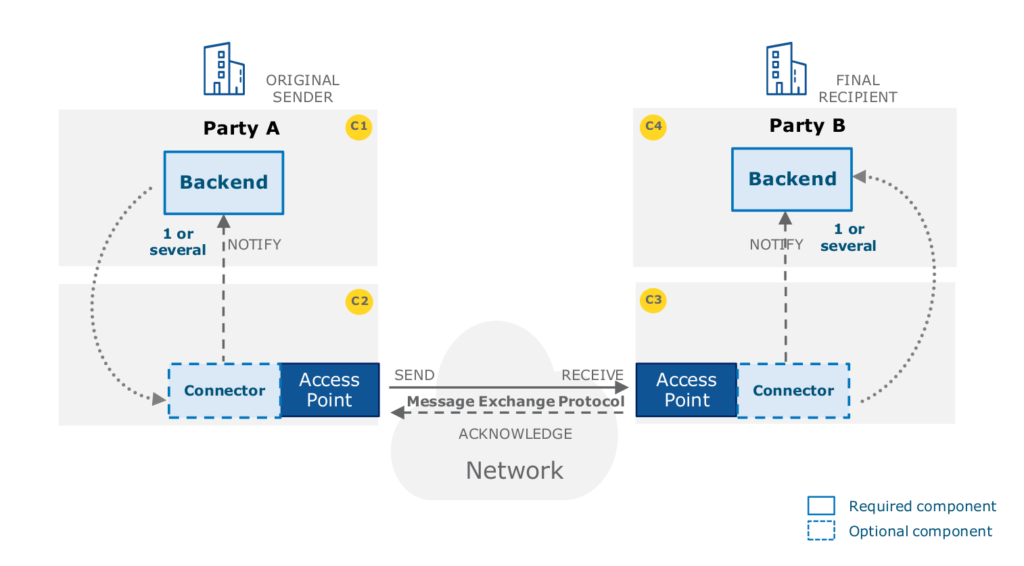
]14 La topologie à 4 coins (C1, C2, C3, C4)
Dans cette configuration :
- le système d’information émetteur est le coin 1
- le point d’accès émetteur est le coin 2
- le point d’accès récepteur est le coin 3
- le système d’information récepteur est le coin 4
La Commission européenne a regroupé les informations générales sur la mise en place d’eDelivery dans une présentation au format PDF.
Le message
Le protocole eDelivery se base sur le standard AS4 Profile of ebMS 3.0 Version 1.0 de l’OASIS et est compatible avec SOAP 1.1 ou 1.2. Le résultat est le protocole eDelivery AS4 1.13 du 30 mai 2018. C’est ce protocole qui encadre la communication entre les points d’accès.
Des métadonnées supplémentaires peuvent être ajoutées à un message via un payload standard SBDH (Standard Business Document Header), pour davantage d’opérabilité. Pour plus d’informations, vous pouvez également consulter la foire aux questions consacrée à SBDH.
Enfin, le contenu d’un message eDelivery peut être signé grâce à la technologie ASiC (Associated Signature Containers) afin de garantir l’authenticité du contenu tout au long de sa transmission. C’est donc une alternative à la sécurité fournie par le protocole SOAP. Une foire aux questions est également disponible.
Les points d’accès et le système d’information
Le point d’accès est la brique logicielle qui permet au système d’information d’une administration d’envoyer et de recevoir des messages sur le réseau européen eDelivery. La Commission européenne publie une liste de solutions de point d’accès, dont une, Domibus, est l’implémentation de référence et open source (code source).
La communication entre un système d’information et le point d’accès associé relève du choix de l’administration. Des connecteurs sont disponibles, mais il est également possible de concevoir une connexion directe entre le système d’information et le point d’accès, sans passer par un connecteur. Enfin, un connecteur peut être partagé par plusieurs systèmes d’information.
Découverte des autres points d’accès : statique ou dynamique
eDelivery définit deux méthodes pour déterminer l’adresse IP du point d’accès d’un message et pour récupérer ses métadonnées : l’acquisition statique (static discovery) et l’acquisition dynamique (dynamic discovery).
L’acquisition statique repose sur le protocole DNS, le même protocole utilisé pour le Web, qui permet de déterminer une adresse IP à partir d’un nom de domaine associé. L’inconvénient est que la mise à jour des enregistrements DNS peut prendre quelques heures en cas de changement d’adresse IP du point d’accès.
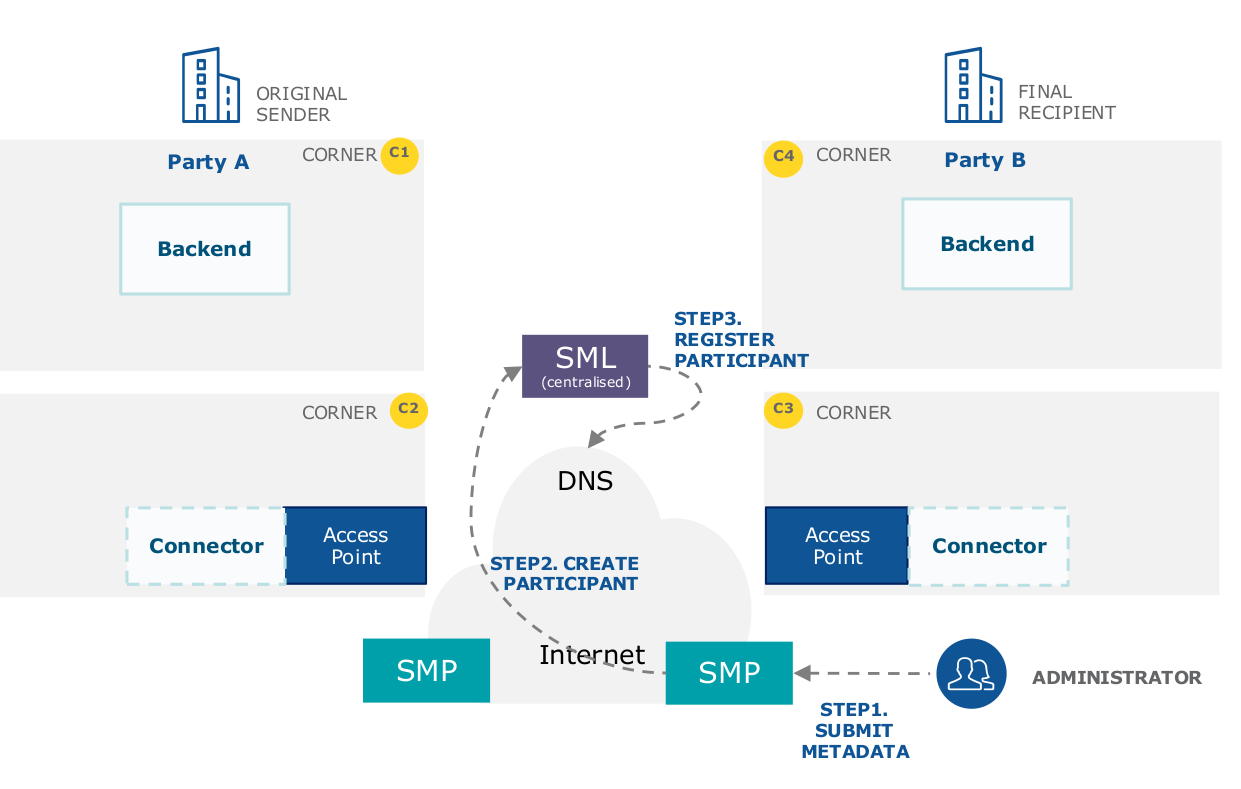
L’acquisition dynamique repose sur un service de publication des métadonnées (Service Metadata Publisher, SMP) combiné à un service de localisation (Service Metadata Locator, SML) partagé. Les administrations participant au réseau eDelivery sont invitées à publier les données de leurs points d’accès via un service SMP. Elles reçoivent alors un identifiant qui facilite sa découverte, améliore la visibilité des capacités des points d’accès du réseau et diminue la dépendance au protocole DNS.
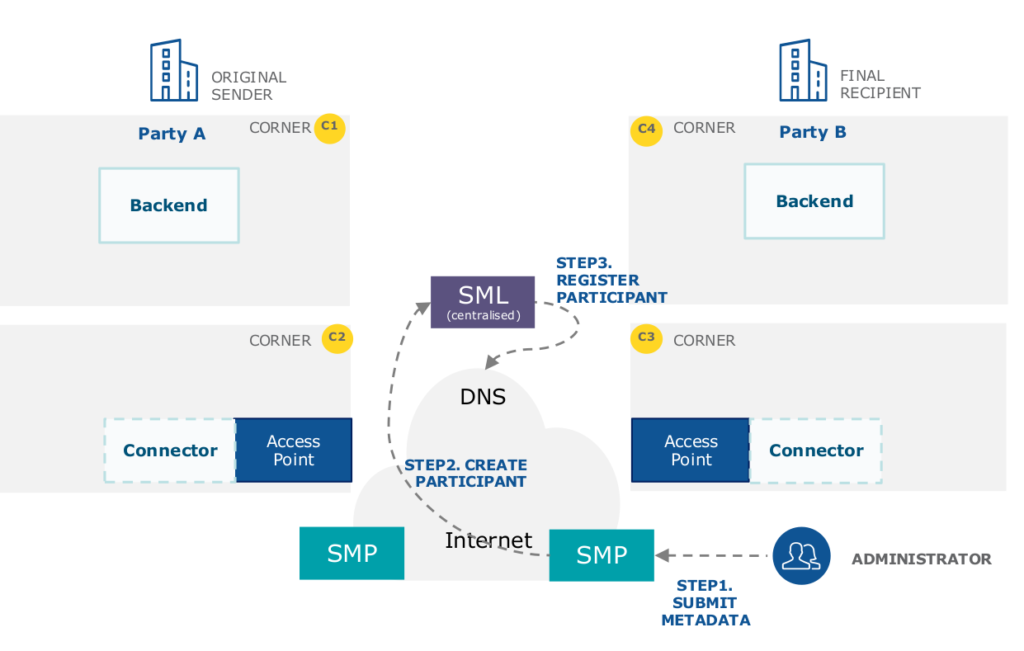
]26 L’enregistrement d’un point d’accès auprès d’un SML via un SMP
Lien avec TOOP
Le TOOP, « The Once-Only Principle » (le principe « une seule fois »), est un projet lancé par la Commission européenne le 1er janvier 2017. Appliqué au service public, ce principe signifie que les entreprises et les particuliers n’aient à fournir un même justificatif qu’une seule fois.
Le projet TOOP est coordonné par la Tallinn University of Technology, et repose sur eDelivery pour le partage d’informations entre administrations publiques.
En France, ce principe est matérialisé par le programme « Dites le nous une fois ».
Questions en suspens
- Quel est la différence entre le protocole PEPPOL utilisé par OpenPEPPOL pour la commande publique électronique, et e-SENS, poussé par la réglementation CEF et déjà utilisé par e-CODEX ? Les deux se basent sur le standard OASIS AS4.
- Sur la page de la spécification d’e-SENS AS4 1.12, il est indiqué que cette spécification est dépréciée par eDelivery AS4 1.13. Pourquoi ce renommage ? eDelivery remplace e-SENS ?

{kind=link}
{kind=link}